대규모 언어모델(LLM)은 현지 언어 설문 응답을 얼마나 잘 분석할 수 있을까?

글_ 투샤르 싱(Tushar Singh), 히만슈 쿠마르(Himangshu Kumar)
농식품 시스템(Food Systems) 연구를 비롯한 정책·개발 연구는 주로 구조화된 설문조사, 행정 데이터, 실험 연구에 의존하고 있습니다. 이러한 접근법은 정량적 분석에는 강점을 가지고 있지만, 현장의 맥락과 경험을 담고 있는 정성적 정보까지 충분히 포착하기에는 한계가 있습니다.
이러한 한계를 보완하는 대표적인 방법이 개방형(Open-ended) 인터뷰 질문입니다. 특히 응답자의 모국어로 수집된 자유서술형 답변은 소농들이 직면한 지역적 문제와 같은 복잡한 현실을 보다 풍부하고 세밀하게 보여주고 있습니다.
그러나 자유형 텍스트 데이터 분석에는 많은 비용과 시간이 소요되며, 분석자에 따라 결과가 달라질 수 있다는 문제도 존재합니다. 응답이 지역 언어나 상대적으로 사용자가 적은 언어로 작성된 경우에는 이러한 어려움이 더욱 커질 수 있습니다.
최근 생성형 AI(Generative AI), 특히 대규모 언어모델(LLM)의 발전은 이러한 문제를 해결할 새로운 가능성을 제시하고 있습니다. 오늘날 다양한 AI 서비스의 기반이 되는 LLM은 방대한 인터넷 텍스트 데이터를 학습해 사람과 유사한 언어 이해 및 생성 능력을 갖추고 있으며, 정성 데이터 분석을 더욱 빠르고 저렴하며 일관성 있게 수행할 수 있는 잠재력을 보여주고 있습니다.
다만 대부분의 LLM 학습 데이터는 영어 중심으로 구성되어 있으며, 지역 언어나 소수 언어는 충분히 반영되지 못하고 있습니다. 따라서 현지 언어 기반 텍스트 분석에서 실제로 얼마나 효과적으로 작동할 수 있는지는 여전히 중요한 연구 과제로 남아 있습니다.
그렇다면 이러한 AI 모델은 저소득·중소득 국가의 농업 및 식품시스템 연구에서도 활용될 수 있을까요?
연구진의 결론은 가능성이 충분하다는 것입니다. 다만 몇 가지 중요한 전제가 따르고 있습니다.
연구진은 스와힐리어(Swahili) 인터뷰 응답을 대상으로 다양한 LLM의 분류 성능을 평가했습니다. 실험 결과, 응답자의 직업을 분류하는 작업에서 AI 모델은 인간 코더의 결과와 약 80~87% 수준의 일치율을 보였습니다. 다만 여전히 인간의 검토와 관리가 필요한 것으로 나타났습니다.
스와힐리어를 대상으로 한 실험
스와힐리어(Swahili)는 동아프리카 전역에서 약 1억 명 이상이 사용하는 언어입니다. 그러나 인터넷상에서 축적된 디지털 데이터 규모는 상대적으로 크지 않습니다.
이처럼 사용 인구는 많지만 온라인 데이터가 부족한 언어는 일반적으로 ‘저자원 언어(Low-resource Language)’로 분류됩니다. 이는 학습용 데이터가 충분하지 않거나, 언어가 사용되는 사회·문화적 맥락이 데이터에 제대로 반영되지 못한 경우를 의미합니다.
연구진은 탄자니아 전화 설문조사 데이터를 활용해 다음과 같은 AI 모델들을 비교 분석했습니다.
- OpenAI GPT-3.5
- OpenAI GPT-4
- OpenAI GPT-4o
- Anthropic Claude 3.5 Sonnet
- Anthropic Claude Haiku
- Mistral 오픈소스 모델
모든 모델은 API(Application Programming Interface)를 통해 활용됐습니다.
비교 기준(Benchmark)으로는 스와힐리어 전용 텍스트 분류 모델도 함께 평가했습니다.
실험 데이터는 응답자의 주 직업을 설명하는 4,000건 이상의 자유응답으로 구성됐으며, 인간 코더가 이미 21개 직업군으로 분류한 상태였습니다.
AI 모델은 각 응답을 읽고 21개 직업군 중 하나를 선택하도록 지시받았으며, AI 결과와 인간 코더의 결과가 일치하는 비율을 정확도로 계산했습니다.
제로샷과 퓨샷(Few-shot) 방식 비교
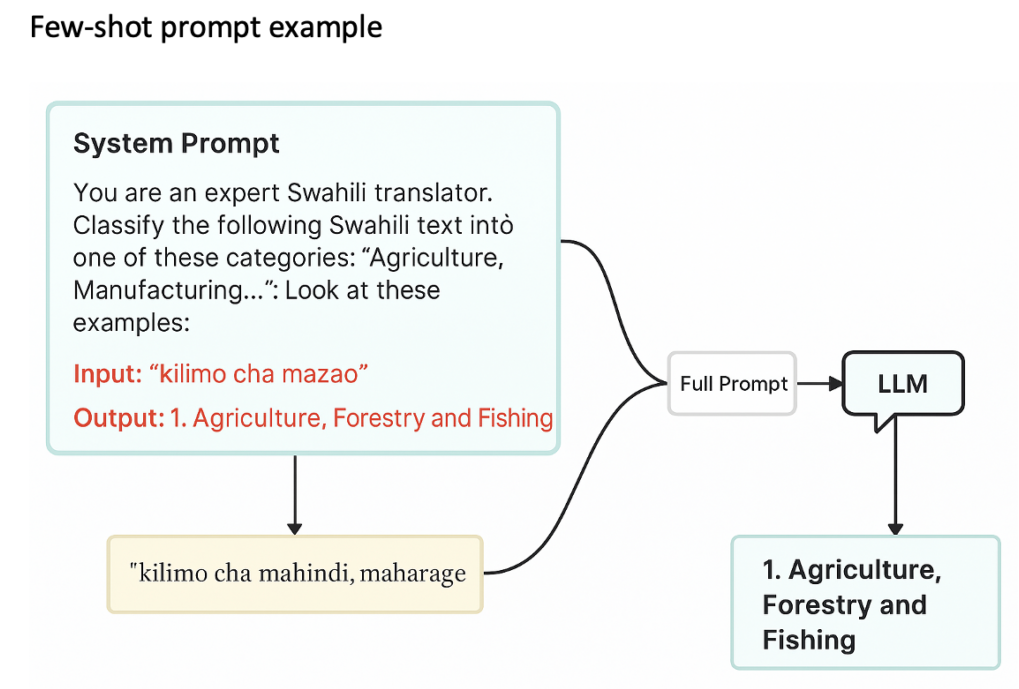
그림 1. 퓨샷 프롬프트 사례 (출처. 저자 작성)
연구진은 두 가지 프롬프트 방식을 비교했습니다.
제로샷(Zero-shot)
AI에게 예시를 제공하지 않고 곧바로 분류를 요청하는 방식입니다.
퓨샷(Few-shot)
몇 개의 정답 예시를 제공한 후 분류를 요청하는 방식입니다.
또한 OpenAI API의 ‘Function Calling’ 기능을 활용해 모델이 미리 정의된 직업군 중에서만 답변하도록 제한했습니다. 이를 통해 응답 형식을 표준화하고 분류 오류를 줄일 수 있었습니다.
직업 분류를 실험 대상으로 선정한 이유
많은 설문조사는 사전에 정의된 직업 목록을 사용하지만, 대규모 가구조사나 인구조사에서는 보다 정확한 정보를 얻기 위해 자유응답 형태를 활용하는 경우가 많습니다.
특히 탄자니아 사례와 같은 전화조사에서는 수십 개의 직업 목록을 일일이 읽어주는 것이 현실적으로 어렵습니다.
따라서 조사원은 응답자의 답변을 그대로 기록하게 되며, 이후 사람이 일일이 직업군으로 분류해야 합니다.
이 과정은 AI가 해결할 수 있는 대표적인 병목 지점 가운데 하나입니다.
이러한 논리는 직업 정보뿐 아니라 다음과 같은 다양한 개방형 질문에도 적용될 수 있습니다.
- 기후변화 영향
- 생계 전략
- 농업 경영 애로사항
- 정책 인식
- 기술 수용 태도

언어모델은 텍스트를 어떻게 이해할까?
언어모델은 텍스트를 읽을 때 단어와 문장을 ‘임베딩(Embedding)’이라는 고차원 벡터로 변환합니다.
예를 들어 ‘커피 재배’라는 표현은 수많은 숫자로 구성된 벡터 형태로 저장됩니다.
의미가 비슷한 단어들은 공간상에서 가까운 위치에 배치됩니다.
예를 들어 ‘커피 재배’와 ‘옥수수 재배’, ‘쌀 농사’와 ‘채소 재배’는 서로 가까운 위치에 존재합니다.
반면 ‘커피 재배’와 ‘교사’처럼 의미가 크게 다른 개념은 멀리 떨어져 배치됩니다.
연구진은 이러한 임베딩을 2차원 공간으로 시각화해 AI가 직업군을 어떻게 인식하는지 분석했습니다.
그 결과 농업 분야 응답은 하나의 군집(cluster)으로 모이는 경향을 보였습니다.
반면 ‘닭 판매’와 같은 응답은 농업과 소매업 어느 쪽으로도 해석될 수 있어 두 군집 사이에 위치하는 모습을 나타냈습니다.
또한 짧거나 특이한 답변은 충분한 문맥이 없어 다른 응답들과 떨어진 위치에 분포하는 경향을 보였습니다.
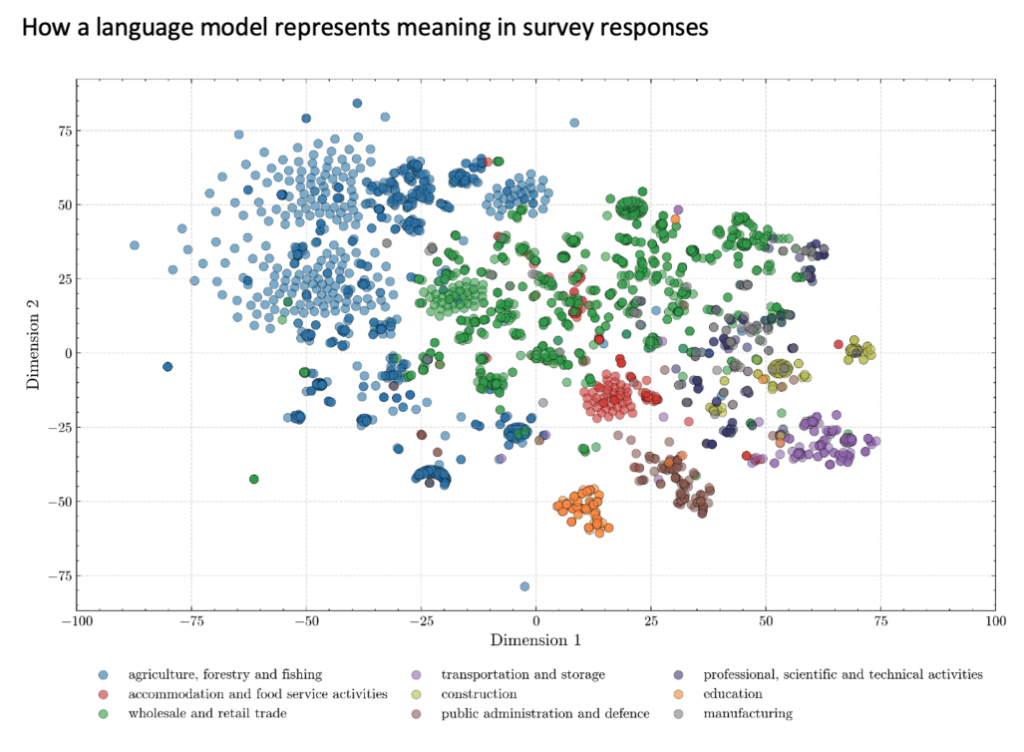
그림 2. 언어모델의 설문 응답 의미 표현 방식 (출처: 저자 작성)
AI 모델의 성능은 어느 정도였을까?
전체적으로 AI 모델은 사람이 직접 분류한 결과와 80~87% 수준의 일치율을 보였습니다.
가장 우수한 성능을 보인 모델은 Claude 3.5 Sonnet과 GPT-4였습니다.
특히 퓨샷(Few-shot) 방식에서 성능이 더욱 향상됐습니다.
GPT-3.5와 Claude Haiku 역시 양호한 성능을 보였으며, GPT-4o는 다소 낮은 정확도를 기록했습니다.
Mistral 계열 모델은 초기 제로샷 성능은 낮았지만, 예시를 제공한 이후 성능이 크게 향상됐습니다.
흥미로운 점은 비교 기준으로 사용한 스와힐리어 전용 모델의 정확도가 89.3%로 가장 높았다는 점입니다.
다만 이 모델은 특정 언어에 맞춰 별도로 학습된 전용 모델이기 때문에 여러 언어와 다양한 업무에 적용 가능한 범용 LLM과 직접 비교하기에는 한계가 있습니다.
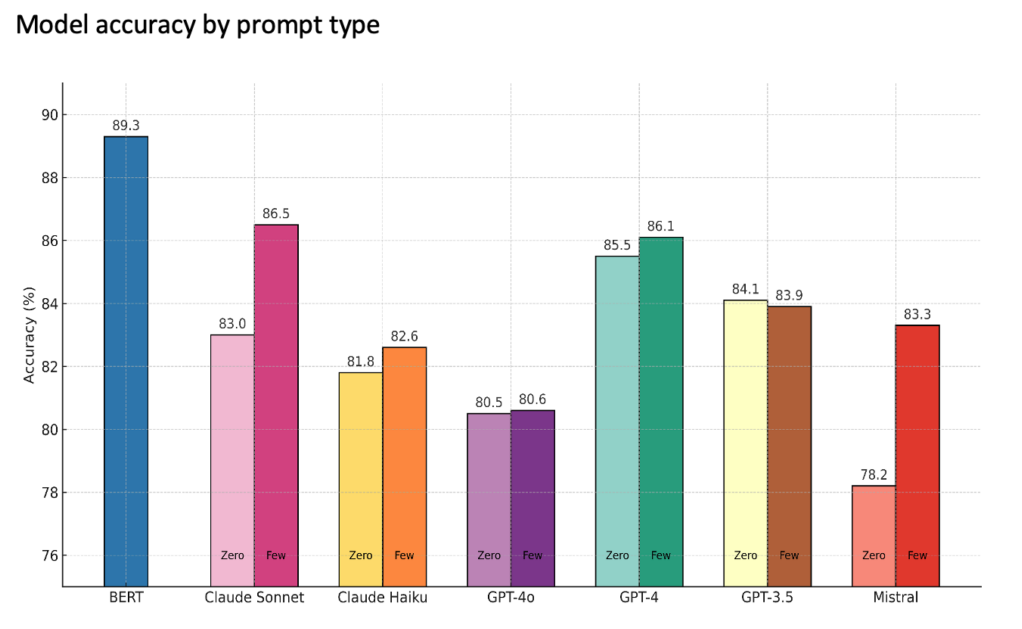
(자료: 저자 작성)
AI는 어떤 경우에 실수했을까?
자유응답 텍스트를 해석하는 일은 인간에게도 쉽지 않습니다.
많은 응답에는 지역 특유의 표현이나 맥락 의존적인 의미가 포함돼 있었습니다.
인간 코더는 응답자의 말투, 후속 질문 결과, 다른 설문 문항 정보 등 다양한 추가 정보를 활용할 수 있습니다.
반면 LLM은 단일 응답만 독립적으로 분석하기 때문에 이러한 맥락을 활용하기 어렵습니다.
주요 오류 사례는 다음과 같습니다.
첫째, 응답이 지나치게 짧은 경우입니다. 정보가 부족해 정확한 분류가 어려웠습니다.
둘째, 여러 범주에 동시에 속할 수 있는 경우입니다. 예를 들어 ‘닭을 판매한다’는 응답은 농업 또는 소매업으로 모두 해석될 수 있습니다.
셋째, 응답이 지나치게 긴 경우입니다. 핵심 정보 외의 부가 설명이 모델의 판단을 혼란스럽게 만들었습니다.
퓨샷(Few-shot) 방식은 정확도를 높이는 데 도움이 됐지만 이러한 문제를 완전히 해결하지는 못했습니다.
Table 1
| Swahili Response | English Translation | Human Category | LLM Category |
|---|---|---|---|
| hifadhi ya taifa | National park | Transportation and storage | Public administration |
| Ufundi | Craftsmanship | Construction, Professional/Technical | Construction |
Source: Authors Get the data
연구와 실무에 주는 시사점
이번 연구는 LLM이 개방형 설문 응답 분석에 상당한 가능성을 보여주고 있음을 시사합니다.
AI는 수천 건의 응답을 몇 분 만에 처리할 수 있으며, 연구자가 수행해야 하는 반복적인 분류 작업을 크게 줄일 수 있습니다.
그러나 여전히 애매하거나 맥락 의존적인 응답에서는 인간의 판단이 필요합니다.
연구진은 다음과 같은 실무적 활용 방안을 제안했습니다.
- 프롬프트에 3~5개의 명확한 예시를 포함합니다.
- JSON 등 정형화된 출력 형식을 활용합니다.
- 분류 이유를 함께 설명하도록 요청합니다.
- 희귀 사례를 충분히 포함해 테스트합니다.
- 처리 시간과 토큰 사용량을 기록합니다.
- 프롬프트와 모델 버전을 문서화합니다.
이러한 방법은 정확도를 높이고 향후 동일한 결과를 재현하는 데 도움이 될 수 있습니다.
Table 2
| What to try | Why it helps |
|---|---|
| Add 3–5 clear examples to your prompt | Gives the model helpful references, so it can better understand how to respond |
| Ask for the answer in a set format if the model allows (e.g., JSON or standardized fields) | Helps get consistent, predictable responses that are easier to read, reuse, or process automatically |
| Ask the model to explain its answer, especially when responses are unclear | Helps you understand its reasoning and spot mistakes |
| Include more examples of rare or unusual answers when testing the model | Helps you check whether the model can handle edge cases, not just the most common ones |
| Keep track of how long responses take and how much text is used | Helps you estimate time and cost when scaling up |
| Write down which prompt, temperature setting (a term for randomness), and model version you used | Makes it easier to repeat results later, even if the model changes |
Source: Authors Get the data
가장 현실적인 접근은 ‘인간+AI 협업’
비용 역시 중요한 변수입니다.
Claude 3.5 Sonnet이나 GPT-4와 같은 고성능 모델은 정확도가 높지만 대규모 데이터 처리 시 비용 부담이 발생합니다.
반면 소형 모델이나 언어 특화 모델은 비용이 낮지만 복잡한 사례에서는 성능이 떨어질 수 있습니다.
따라서 연구진은 가장 현실적인 접근법으로 Human-in-the-Loop(인간 참여형 AI) 방식을 제안했습니다.
이 방식은 AI가 모든 응답을 1차 분류하고, 자신이 확신하지 못하는 응답만 연구자가 검토하는 형태입니다.
이른바 액티브 러닝(Active Learning) 기법을 활용하면 전체 응답 중 약 10~20%의 어려운 사례만 집중적으로 검토하더라도 대부분의 오류를 줄일 수 있습니다.
이는 AI의 처리 속도와 인간의 맥락 이해 능력을 효과적으로 결합하는 방법으로 평가됩니다.
* 저자인 투샤르 싱(Tushar Singh)은 국제식량정책연구소(IFPRI) 자연자원 및 회복력 부문의 선임 연구분석가이며, 히만슈 쿠마르(Himangshu Kumar)는 Atlas Public Policy의 데이터 어소시에이트입니다.
*본 글은 아직 동료심사(peer review)를 거치지 않은 연구를 기반으로 작성되었습니다. 본문에 제시된 견해는 저자 개인의 의견입니다.
*호미농부는 본 게시물을 단순 한글 번역만 진행하였습니다. 본 포스트의 원문은 (여기 링크)에서 확인하실 수 있습니다.


![[현장]”눈 뜬 트랙터, 스스로 길을 만들다” 대동, 국내 최초 비전 AI 트랙터 시연회 개최](https://smartnongup.kr/wp-content/uploads/2025/12/daedong-TG320-auto-tractor-900web.png "[현장]”눈 뜬 트랙터, 스스로 길을 만들다” 대동, 국내 최초 비전 AI 트랙터 시연회 개최")



![[농기평] 인공지능이 농사 고수라고요?](https://smartnongup.kr/wp-content/uploads/2026/02/IPET-top-title-410x260.png "[농기평] 인공지능이 농사 고수라고요?")