안녕하세요, 흙과 기술을 잇는 테크 스토리텔러 호미농부(HomiFarmer)입니다.
오늘은 우리 농업의 미래, 특히 데이터가 부족한 환경이나 소규모 농가(Smallholder)의 목소리를 어떻게 기술로 담아낼 수 있을지에 대한 흥미로운 기술 기사를 소개하고자 합니다. 식량 시스템 연구에서 사람들의 생생한 목소리(질적 데이터)를 AI, 특히 대규모 언어 모델(LLM)을 활용해 분석하는 방법에 대한 글입니다.
탄소 농업이나 정밀 농업 현장에서도 농부들의 경험적 데이터는 매우 중요한데, 이를 분석하는 과정은 늘 시간이 많이 걸리는 일이었죠. 이 글은 스와힐리어(Swahili)라는 구체적인 사례를 들어 AI가 어떻게 언어의 장벽을 넘어 농업 연구를 도울 수 있는지 실증적으로 보여줍니다.
정성적 연구에서의 AI: 대규모 언어 모델(LLM)을 활용한 모국어 설문 응답 코딩
글_ 투샤르 싱(Tushar Singh) & 히망슈 쿠마르(Himangshu Kumar)
제공_ 국제식량정책연구소(International Food Policy Research Institute, IFPRI)
식량 시스템 연구, 더 넓게는 정책 및 개발 연구는 종종 구조화된 설문조사, 행정 데이터 또는 실험에 의존합니다. 이러한 접근 방식은 가치 있는 정량적 통찰력을 제공하지만, 중요한 질적 차원을 놓치는 경향이 있습니다. 유용한 질적 접근 방식 중 하나는 개방형 인터뷰(주관식 질문)입니다. 이러한 응답이 참가자의 모국어로 수집될 경우, 예를 들어 소규모 농가가 직면한 복잡한 현지의 어려움 등에 대해 풍부하고 미묘한 뉘앙스가 담긴 정보를 제공할 수 있습니다.
그러나 자유 형식의 텍스트를 분석하는 것은 비용과 시간이 많이 소요되며, 분석가마다 결과가 일치하지 않을 수도 있습니다. 이러한 문제는 응답이 지역 언어나 널리 사용되지 않는 언어로 되어 있을 때 더욱 두드러집니다.
최근 생성형 인공지능, 특히 대규모 언어 모델(LLM)의 발전은 이러한 문제에 대한 유망한 해결책을 제시합니다. 현재 많은 AI 애플리케이션의 기반 기술인 LLM은 질적 데이터를 더 빠르고 저렴하게, 그리고 잠재적으로 더 일관성 있게 분석할 수 있게 해줍니다. 이러한 모델들은 인터넷에서 수집된 방대한 텍스트 데이터를 바탕으로 일관된 응답을 생성하도록 훈련되었습니다.
하지만 대부분의 LLM 훈련 데이터셋에서는 영어 텍스트가 지배적이며, 다른 언어들은 충분히 대표되지 못하고 있습니다. 따라서 이러한 AI 도구들은 현지 언어로 된 텍스트에서는 잘 작동하지 않을 수 있습니다. 이는 중요한 질문을 제기합니다. “과연 이 모델들이 이러한 장애물을 효과적으로 극복하고 저소득 및 중소득 국가의 식량 시스템 연구를 지원할 수 있을까요?”
우리의 연구 결과는 “그렇다”고 답하지만, 몇 가지 중요한 주의사항이 있습니다. 우리는 다양한 LLM이 스와힐리어(Swahili) 텍스트를 얼마나 잘 분류하는지 평가하기 위한 실험을 설계했습니다. 여기서는 인터뷰 응답에서 직업 범주를 식별하는 작업을 수행했는데, 모델들이 인간이 코딩한 라벨과 대략 80%~87%의 정확도로 일치하는 것을 확인했습니다. 물론 여전히 인간의 감독과 기타 예방 조치가 필요합니다.
우리의 접근 방식
스와힐리어는 동아프리카 전역에서 1억 명 이상이 사용하는 언어이지만, 디지털 발자국(Digital footprint, 디지털상에 존재하는 데이터의 양)은 상대적으로 작습니다. 널리 사용되지만 온라인상의 데이터는 제한적이라는 이러한 특성 덕분에, 스와힐리어는 소위 ‘저자원 언어(Lower-resource languages)’*에 대해 LLM을 테스트하기에 이상적입니다.
저자원 언어(Low-resource languages): AI 모델 훈련에 사용할 수 있는 레이블링 된(정답이 있는) 데이터나 레이블링 되지 않은 텍스트 데이터가 부족하고, 사용 가능한 데이터조차 해당 언어와 사회문화적 맥락을 충분히 반영하지 못하는 언어를 말합니다. [편집자 주]
우리는 탄자니아의 전화 설문 데이터를 사용하여 OpenAI의 GPT-3.5, GPT-4, GPT-4o, Anthropic의 Claude 3.5 Sonnet 및 Haiku, 그리고 Mistral의 오픈 소스 모델들의 성능을 테스트했습니다. 모든 모델은 API(애플리케이션 프로그래밍 인터페이스)를 통해 접근했습니다. LLM을 벤치마킹(기존의 확립된 접근 방식과 비교하여 기준점 마련)하기 위해, 우리는 더 작지만 스와힐리어 전용으로 개발된 텍스트 분류 모델도 테스트했습니다. 데이터셋에는 응답자의 주된 직업을 설명하는 4,000개 이상의 개방형 응답이 포함되어 있었으며, 이는 인간 코더(분석가)들에 의해 21개의 직업 범주로 분류된 상태였습니다. 각 모델에게는 각 응답에 대해 이러한 범주 중 하나를 할당하도록 지시(프롬프트)했으며, 우리는 모델의 라벨이 인간이 코딩한 직업 범주와 일치하는 비율로 정확도를 측정했습니다.
우리는 두 가지 프롬프트 전략을 비교했습니다.
- 제로 샷(Zero-shot): 예시를 제공하지 않고 분류를 요청하는 방식
- 퓨 샷(Few-shot): 몇 가지 라벨링 된 예시를 함께 제공하는 방식 (그림 1 참조)
또한, 우리는 출력 형식을 제안하는 OpenAI API의 기능인 “함수 호출(function calling)”을 사용하여 모델이 사전에 정의된 라벨만 사용하여 응답하도록 했습니다.
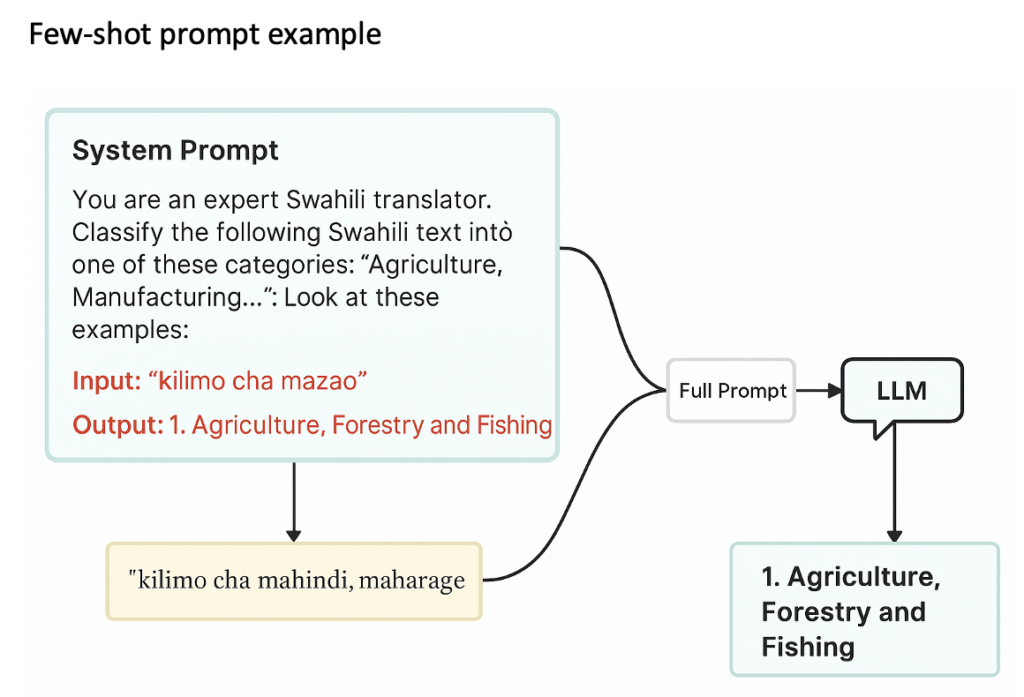
(그림 1 – 원문의 차트 참조) 참고: “kilimo cha mazao”의 영어 번역은 “farming crops(작물 재배)”이고, “kilimo cha mahindi, maharage”는 “corn and bean farming(옥수수 및 콩 재배)”입니다. 출처: 저자
우리는 개념 증명(Proof-of-concept)으로 직업 코딩을 선택했습니다. 많은 설문조사가 사전 코딩된 목록(객관식)을 사용하지만, 대규모 가구 조사나 인구 조사는 뉘앙스를 보존하고 다양한 직업명을 포착하며 유연한 사후 코딩을 가능하게 하기 위해 개방형 응답(주관식)을 수집하는 경우가 많습니다. 마찬가지로 탄자니아 사례와 같은 신속한 전화 설문조사에서도 조사원들은 긴 직업 목록을 일일이 읽어주는 것이 비현실적이기 때문에 응답을 있는 그대로(verbatim) 기록하곤 합니다. 이렇게 기록된 데이터는 수동으로 코딩해야 하는데, 이는 세부 정보를 보존할 수 있지만 후속 작업의 부담을 가중시키고 병목 현상을 만듭니다. 바로 이 지점이 LLM이 해결을 도울 수 있는 부분입니다. 기후 영향, 생계 또는 태도에 관한 다른 개방형 질문들에도 표준화된 사전 코딩이 불가능한 경우가 많으므로 동일한 논리가 적용됩니다.
언어 모델은 텍스트를 어떻게 이해하는가: 임베딩(Embeddings)의 이해
언어 모델이 설문 응답을 어떻게 해석하는지 이해하기 위해, 우리는 모델이 내부적으로 의미를 어떻게 구성하는지 살펴보았습니다. 모델은 본문의 모든 용어(예: “커피 농사”)를 ‘임베딩(Embeddings)’*이라고 불리는 고차원 벡터로 변환합니다. 의미를 공유하는(즉, 의미론적으로 유사한) 응답들은 이 공간에서 서로 가까운 벡터를 생성하는 반면, 매우 다른 개념들은 서로 멀리 떨어지게 됩니다. 예를 들어, “커피 농사”와 “옥수수 농사”는 “커피 농사”와 “교사”보다 의미론적으로 더 가깝습니다.
임베딩(Embeddings): 텍스트와 같은 비정형 데이터를 컴퓨터가 이해하고 계산할 수 있도록 숫자의 나열(벡터)로 변환하는 기술입니다. 단어의 의미나 문맥적 유사성을 수학적 거리에 반영합니다. [편집자 주]
이를 시각화하기 위해 우리는 임베딩을 2차원 표면에 투영했습니다(그림 2 참조).
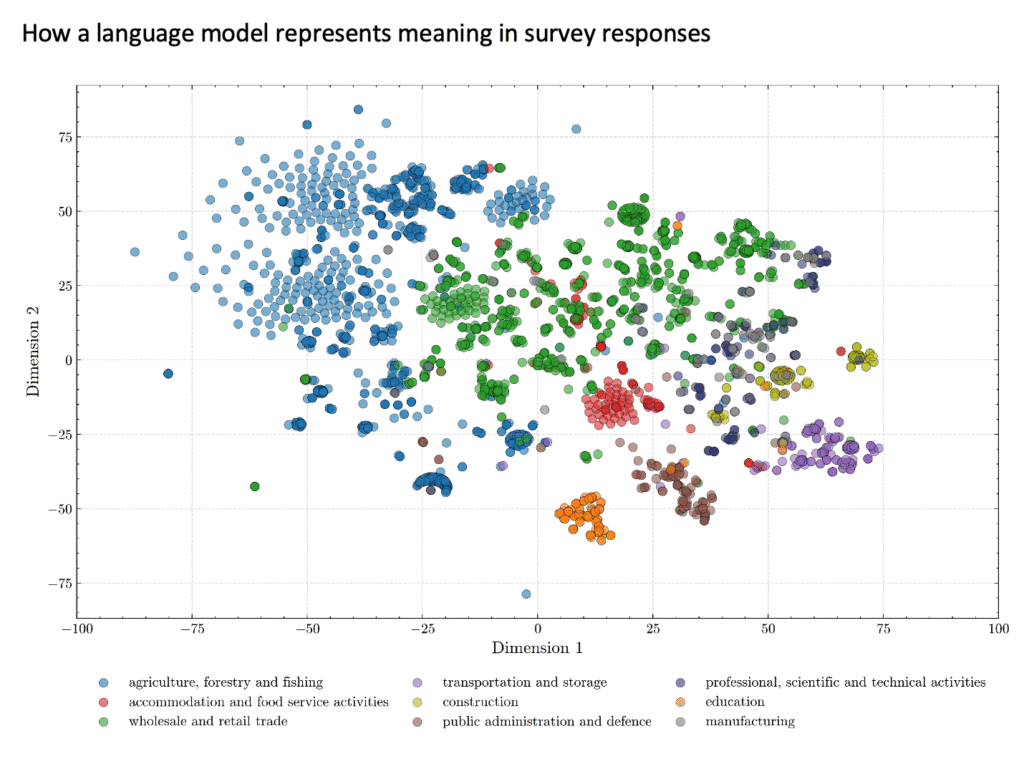
(그림 2 – 원문의 차트 참조) 참고: 임베딩은 BERT 기반 모델을 사용하여 생성되었으며, 시각화를 위해 t-SNE를 사용하여 2차원으로 축소되었습니다. 출처: 저자
플롯(그림)에서 각 점은 스와힐리어 직업 설명을 나타내며, 인간 코더가 할당한 직업에 따라 색상으로 구분되어 있습니다. 같은 색상의 클러스터(무리지어 있는 것)는 모델이 해당 응답들을 의미론적으로 유사하게 보고 있음을 시사합니다. 예를 들어, 농업 부문의 직업을 나타내는 많은 파란색 점들이 함께 나타납니다. 색상이 섞이거나 겹치는 부분은 모호함을 나타내는데, 예를 들어 “닭 판매”는 소매업이나 농업 중 하나에 속할 수 있기 때문입니다. 고립된 점들은 종종 명확한 분류를 위한 문맥이 부족한 짧거나 특이한 응답을 나타냅니다.
모델의 성능은 어떠했나?
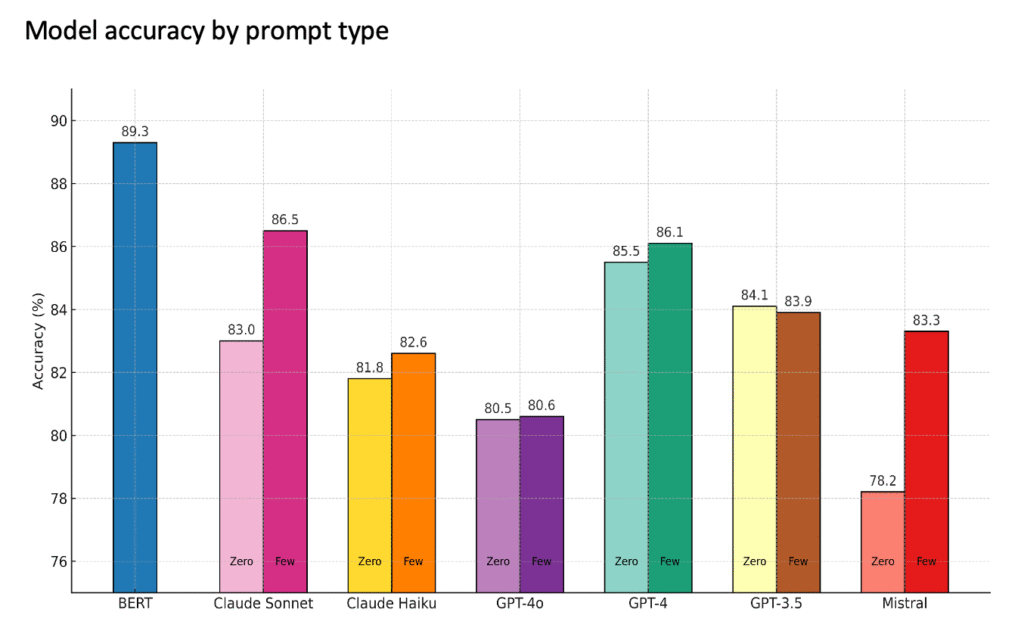
전반적으로 언어 모델들은 80~87%의 사례에서 인간이 할당한 직업 범주와 일치했습니다(그림 3 참조). Claude 3.5 Sonnet과 OpenAI의 GPT-4가 가장 좋은 성능을 보였으며, 특히 몇 가지 라벨링 된 예시를 제공했을 때(Few-shot) 더욱 그러했습니다. GPT-3.5와 Claude Haiku도 좋은 성과를 보였고, GPT-4o는 약간 낮은 정확도를 보였습니다. Mistral 모델들은 더 작고 덜 전문화되었음에도 불구하고, 제로 샷 결과는 약했지만 퓨 샷 프롬프트를 사용했을 때 상당히 개선되었습니다.
벤치마크로 사용한 모델(스와힐리어 전용 모델)은 더 높은 정확도(89.3%)를 달성했지만, 여러 언어와 작업에 적용할 수 있는 LLM과 달리 이 모델은 스와힐리어에 특별히 맞춤화되고 라벨링 된 예시로 훈련되었기 때문에 일반화(generalize) 능력은 떨어질 수 있습니다.
모델은 어디서 실수를 했나?
비공식적이고 개방형인 응답을 해석하는 것은 본질적으로 어려운 일입니다. 많은 응답이 지역적 표현이나 문맥에 의존하는 어구를 포함하고 있습니다. 인간 코더들은 종종 정확한 범주를 할당하기 위해 어조, 후속 질문, 또는 관련 설문 모듈과 같은 추가 정보에 의존합니다. 그러나 LLM은 각 응답을 고립된 상태(in isolation)로 처리하므로, 모호하거나 미묘한 응답을 올바르게 분류하는 능력이 제한됩니다.
대부분의 오류는 다음과 같은 경우에 발생했습니다:
- 응답이 짧거나 모호하여 정보가 너무 적을 때.
- 직업이 여러 범주에 속할 수 있을 때 (예: “닭 판매”는 농업 또는 소매업으로 분류될 수 있음).
- 긴 답변에 모델을 혼란스럽게 하는 추가 세부 정보가 포함되어 있을 때.
퓨 샷(Few-shot) 프롬프팅은 정확도를 높였지만 이러한 문제를 완전히 해결할 수는 없었습니다. 표 1의 예시에서 볼 수 있듯이, 인간 코더들은 종종 모델이 접근할 수 없는 추가적인 문맥에 의존했습니다.
표 1.
| 스와힐리어 응답 (Swahili Response) | 영어 번역 (English Translation) | 인간 분류 (Human Category) | LLM 분류 (LLM Category) |
| hifadhi ya taifa | National park (국립공원) | Transportation and storage (운송 및 보관) | Public administration (공공 행정) |
| Ufundi | Craftsmanship (기술/공예) | Construction (건설) | Professional/Technical (전문/기술직) |
(출처. 저자)
연구 및 실무에 주는 시사점
우리의 연구 결과는 개방형 설문 응답을 코딩하는 데 LLM을 사용하는 것의 가능성과 한계를 모두 보여줍니다. 이러한 모델은 수천 개의 답변을 몇 분 만에 처리하여 수동 작업 노력을 획기적으로 줄일 수 있습니다. 그러나 인간 면접관이라면 대화 중에 명확히 할 수 있었을 모호하거나 문맥 의존적인 답변에 대해서는 여전히 어려움을 겪습니다.
이러한 트레이드오프(상충 관계)를 조율하는 데 도움을 주기 위해, 우리는 아래에 몇 가지 실용적인 전략을 제시합니다 (표 2):
표 2: 실용적인 전략
| 시도해 볼 것 (What to try) | 도움이 되는 이유 (Why it helps) |
| 프롬프트에 3~5개의 명확한 예시 추가 | 모델에게 유용한 참조(레퍼런스)를 제공하여, 어떻게 응답해야 할지 더 잘 이해하게 합니다. |
| 모델이 허용하는 경우 정해진 형식(예: JSON 또는 표준화된 필드)으로 답변 요청 | 읽기 쉽고, 재사용하거나 자동으로 처리하기 쉬운 일관되고 예측 가능한 응답을 얻는 데 도움이 됩니다. |
| 특히 응답이 불명확할 때, 모델에게 답변에 대한 설명을 요청 | 모델의 추론 과정을 이해하고 실수를 발견하는 데 도움이 됩니다. |
| 모델 테스트 시 희귀하거나 특이한 답변 예시를 더 많이 포함 | 모델이 가장 흔한 경우뿐만 아니라 ‘엣지 케이스(Edge cases)’*(이례적인 상황)도 처리할 수 있는지 확인하는 데 도움이 됩니다. |
| 응답에 걸리는 시간과 텍스트 사용량을 추적 | 규모를 확장(Scaling up)할 때 시간과 비용을 추산하는 데 도움이 됩니다. |
| 사용된 프롬프트, 온도 설정(Temperature setting, 무작위성을 나타내는 용어)*, 모델 버전을 기록 | 모델이 변경되더라도 나중에 결과를 재현하기 쉽게 만듭니다. |
엣지 케이스(Edge cases): 알고리즘이 처리하는 데이터의 범위 중 일반적이지 않거나 극한의 경계에 있어 오류가 발생하기 쉬운 예외적인 상황을 말합니다. [편집자 주]
온도 설정(Temperature setting): AI 모델이 텍스트를 생성할 때 창의성이나 무작위성의 정도를 조절하는 파라미터(매개변수)입니다. 온도가 높으면 더 창의적/무작위적이고, 낮으면 더 보수적/결정론적인 답변을 내놓습니다. [편집자 주]
비용 역시 똑같이 중요한 고려 사항입니다. Claude 3.5 Sonnet이나 GPT-4와 같은 선도적인 모델들은 상대적으로 높은 정확도를 제공하지만 대규모로 사용할 경우 비용이 많이 들 수 있습니다. 더 작거나 특정 언어에 특화된 모델들은 더 저렴하며 몇 가지 라벨링 된 예시가 주어지면 좋은 성능을 낼 수 있지만, 더 까다로운 케이스에서는 종종 어려움을 겪습니다.
따라서 ‘인간 참여형(Human-in-the-loop)’* 접근 방식이 가장 실용적인 전략입니다. 모델이 모든 것을 코딩하게 하되, 모델이 ‘불확실함’으로 표시한 응답은 연구자가 검토하도록 하는 것입니다. ‘능동 학습(Active learning)’은 대부분의 오류를 유발하는 10~20%의 답변을 표면으로 드러내어, 속도와 질적 연구가 요구하는 미묘한 뉘앙스(nuance) 사이의 균형을 맞출 수 있게 합니다.
인간 참여형(Human-in-the-loop): AI 시스템의 학습이나 의사결정 과정에 인간이 개입하여 피드백을 주거나 오류를 수정함으로써 성능을 높이는 방식입니다.
마지막으로, 우리의 실험은 단일 언어(스와힐리어)로 된 하나의 작업(직업 코딩)에 초점을 맞췄습니다. 이는 LLM의 기능에 대한 명확한 기준점을 제공했지만, 연구자들이 직면하는 개방형 질문의 전체 범위를 반영하지는 못합니다. 인식이나 실제 삶의 경험(lived experiences)에 관한 현실 세계의 응답들은 훨씬 더 주관적인 경우가 많습니다.
이러한 영역에서 LLM은 방대한 양의 복잡한 텍스트를 빠르고 일관되게 처리함으로써 더 큰 가치를 제공할 수 있습니다. 즉, 그렇지 않았다면 간과되거나 일관성 없이 해석되었을 미묘한 의미, 감정적 신호, 문화적 참조 등을 체계적으로 식별해 내는 것입니다. 이는 더 많은 연구가 필요한 영역입니다. 우리는 이번 연습이 향후 더 풍부하고 복잡한 설문 질문에 LLM을 적용하는 데 유용한 템플릿(본보기)이 되기를 바랍니다.

*이 글의 저자인 투샤르 싱(Tushar Singh)은 국제식량정책연구소(IFPRI) 천연자원 및 회복력 부서의 선임 연구 분석가입니다. 히망슈 쿠마르(Himangshu Kumar)는 아틀라스 퍼블릭 정책(Atlas Public Policy)의 데이터 어소시에이트입니다. 이 포스트는 아직 동료 검토(Peer-review)를 거치지 않은 연구를 기반으로 합니다. 제시된 의견은 저자들의 것입니다.
*호미농부는 본 게시물을 원문에 충실하게 한글 번역하였으며, 일부 추가 설명이 필요한 경우에 한해서 [편집자 주]를 표기하고 설명을 덧붙였습니다. 본 포스트의 원문은 (여기 링크)에서 확인하실 수 있습니다.


![[분석] EU 농업, 기후변화에 연간 26조 원 증발.. ‘보험 안전망’ 붕괴 경고](https://smartnongup.kr/wp-content/uploads/2025/09/Gemini_Generated_Image_agriculture-risk.png "[분석] EU 농업, 기후변화에 연간 26조 원 증발.. ‘보험 안전망’ 붕괴 경고")

![[카드뉴스] 농업전망 2026 세부 프로그램 및 무료 등록 안내](https://smartnongup.kr/wp-content/uploads/2026/01/card0.png "[카드뉴스] 농업전망 2026 세부 프로그램 및 무료 등록 안내")
